Part VI — Design Principles for Adaptive Governance Architectures
The diagnosis is structural. A governance system that cannot learn—that starves exploration, locks in obsolete models, forgets faster than it learns, or blocks the translation of knowledge into action—has a finite operational lifetime in an environment that changes faster than architectures can be redesigned. The failure modes of Part III are the signatures of a learning architecture that has been left to chance, subjected to political incentives that systematically penalise the variance on which learning depends, and deprived of the institutional machinery that would protect it.
This part turns from diagnosis to prescription. It specifies the design principles that follow from the formal framework and that a governance architecture must satisfy if it is to learn stably over time. The principles are not a blueprint. The appropriate learning architecture for any specific governance function depends on the rate of environmental change in that domain, the cost structure of experimentation, and the existing institutional substrate. What the principles provide is a set of structural requirements that any adaptive governance architecture must meet, and a vocabulary for designing institutions that meet them.
6.1 Protected Experimental Spaces with Persistent Excitation
The persistence of excitation condition (Section 2.4) establishes that a controller must maintain sufficient variation in its input signal to identify the parameters of the system it governs. The governance analogue is that a governance system must maintain a sustained programme of experimentation—policy variation across jurisdictions, pilot programmes, alternative delivery models—to remain calibrated to a changing environment.
The series has already identified protected experimental spaces as the convergent first step across all country cases. Paper VII documented their role as bypass mechanisms that route around dysfunctional central architectures and generate legible evidence about what works. Paper IX reframed them as transition mechanisms that build demonstrated value before scaling. This paper provides the formal rationale: experimental spaces are the governance analogue of the persistent excitation signal in adaptive control. They generate the independent variation in policy design, implementation context, and evaluation methodology that is required to identify the system's operating parameters.
The design requirements follow from the formal condition. The excitation must be persistent—not a one‑off pilot that is either terminated or scaled and never repeated, but a permanent feature of the governance architecture. The excitation must be spanning—the experimental portfolio must cover the dimensions of the system's dynamics that are most uncertain and most consequential for future performance. A system that experiments only with marginal programme adjustments while leaving its fundamental regulatory models, fiscal frameworks, and institutional structures untouched is not satisfying the spanning condition; it is exploring within a box whose walls it never tests. The excitation must be protected—the experimental spaces must be insulated from the short‑term political incentives that would extinguish them when they produce uncomfortable results or when budgets tighten. Protection requires independent funding, statutory mandates, and leadership appointment processes that are decoupled from the political cycle.
The municipal laboratory, the sandbox state, the Special Economic Zone, the pilot programme with randomised evaluation, the regulatory sandbox for financial or technological innovation—each is an institutional form of the persistent excitation principle. None is sufficient alone. The architecture requires a portfolio of such spaces, operating at different scales and in different domains, collectively providing the excitation that keeps the governance system's parameters identifiable.
6.2 Safe‑to‑Fail Structures
Persistent excitation inherently generates errors. Exploration means trying things that might not work, and some of them will not work. If every failure is politically or institutionally catastrophic—if a failed pilot programme ends careers, if a negative evaluation triggers a media firestorm, if an experimental policy that produces adverse outcomes generates lawsuits and compensation claims—then the rational response, under the incentive structure of real governance institutions, is to stop exploring.
The design response is safe‑to‑fail structures: bounded experimental environments where failure is survivable and informative rather than catastrophic. This is the governance analogue of the engineering distinction between fail‑safe and safe‑to‑fail design. A fail‑safe system attempts to prevent failure entirely. A safe‑to‑fail system accepts that failure will occur and designs the system's boundaries so that failure is contained, its consequences are limited, and the information it generates is captured.
The structural properties of a safe‑to‑fail experimental space include:
Bounded scope. The experiment operates on a limited population, in a limited geography, or for a limited duration. The failure of a municipal pilot programme affects thousands, not millions. The failure of a time‑limited regulatory sandbox entry does not restructure an entire industry. The boundary contains the blast radius.
Pre‑committed evaluation and exit. The conditions under which the experiment will be judged a success or a failure are specified in advance, as are the consequences of each. A programme that fails to meet its pre‑registered success criteria is terminated, not because a political adversary demands it but because the architecture mandates it. The termination is not a scandal; it is the system operating as designed. Pre‑commitment protects the experiment from post‑hoc politicisation of its results and from the sunk‑cost fallacy that turns pilot programmes into permanent, unevaluated entitlements.
Institutionalised learning extraction. The information generated by a failure is captured and retained regardless of the programme's fate. A programme that is terminated for failing to meet its objectives nevertheless contributes to the system's knowledge stock if the reasons for its failure are documented, analysed, and integrated into the model that guides future design. The failure is not a waste; it is a measurement.
Insulation of experimenters. The officials who design and implement experiments must be protected from career damage when experiments fail. If the personal consequences of a failed experiment are severe, the only experiments that will be proposed are those that are virtually certain to succeed—which means they are not experiments in any meaningful sense, because they generate no information about the boundaries of the system's dynamics. Protection does not mean immunity from accountability for misconduct or incompetence. It means that a well‑designed experiment that produces a null or negative result is treated as a successful contribution to the system's knowledge, not as a career‑ending mistake.
Safe‑to‑fail structures are the institutional precondition for persistent excitation. Without them, the exploration variance ση2 will be driven to zero by the asymmetric costs of failure. With them, the system can sustain the rate of experimentation that the environment's rate of change demands.
6.3 Separation of Exploration and Exploitation Functions
The dual control framework formalises the tension between exploration and exploitation. A single controller cannot simultaneously optimise for short‑term performance and long‑term learning, because the actions that maximise one are not the actions that maximise the other. The tension is not a design flaw; it is a structural feature of any learning system. The design response is functional separation.
Separation of exploration and exploitation functions means that different institutions are responsible for generating knowledge and for applying it. The exploration institutions—foresight bodies, audit offices, evaluation agencies, experimental programme units, citizens' assemblies, challenge panels—have a mandate to generate information, not to deliver outcomes. Their performance is judged on the quality and relevance of the knowledge they produce, not on the outcomes of the programmes they study. The exploitation institutions—line ministries, delivery agencies, regulatory bodies—have a mandate to deliver outcomes using the best available knowledge, not to generate new knowledge. Their performance is judged on the outcomes they achieve, not on the novelty of their methods.
The separation is not absolute. Exploitation institutions must retain the capacity to absorb and act on the knowledge that exploration institutions produce—the exploitation lock‑in failure mode of Section 3.3 is precisely the decoupling of these functions. And exploration institutions must be connected enough to the operational realities of governance that the knowledge they produce is relevant to the decisions that exploitation institutions face. The design challenge is to maintain sufficient separation to protect exploration from the short‑term pressures that would extinguish it, while maintaining sufficient integration to ensure that what is learned is used.
The organisational forms that achieve this balance vary across governance contexts. The independent central bank is a partial instance: it is separated from the political exploitation apparatus (the treasury, the executive) and given a mandate to pursue a specific objective using its own analytical capacity, with its own exploration function embedded in its research departments. The supreme audit institution is another: it is separated from the agencies it audits and given a mandate to generate information about their performance, not to deliver their programmes. The parliamentary technology assessment body, the independent fiscal council, the citizens' assembly on a specific policy question—each is an exploration institution separated from the exploitation apparatus whose models it may challenge.
The structural requirement is that exploration institutions have protected budgets, statutory independence, and leadership appointment processes that are insulated from the exploitation institutions they are meant to inform. An exploration body whose budget is controlled by the ministry whose programmes it evaluates, or whose director is appointed by the executive whose models it challenges, is an exploration body in name only. Its exploration variance will be driven toward zero by the same incentives that produce exploration starvation in the undifferentiated controller.
6.4 Protected Curiosity Budgets
Why explore? The dual control framework answers: because exploration generates information that improves future performance, and the expected value of that information justifies the short‑term cost of acquiring it. But this answer assumes an institutional environment in which the future benefits of exploration are internalised by the actors who bear its present costs. In most governance systems, they are not. The politician who funds an experimental programme whose benefits will accrue after the next election, or the civil servant who champions a pilot whose results will be available after their next rotation, is bearing costs for benefits that will be captured by others. The incentive gradient points toward under‑exploration.
Protected curiosity budgets are the structural response. They are dedicated resource allocations—funding, personnel, organisational bandwidth—that are reserved for activities whose outcomes are uncertain, that are protected from performance‑based review cycles that penalise the variance inherent in exploration, and that are governed by decision processes that explicitly value the information to be acquired rather than only the outcomes to be achieved.
The design properties of an effective curiosity budget include:
Ring‑fencing. The exploration budget is separated from the operational budget and cannot be reallocated to exploitation activities when resources are tight. The separation is structural—different budget lines, different approval processes, different accounting treatment—not merely notional.
Portfolio logic. The curiosity budget is allocated as a portfolio of experiments with different risk profiles, different timescales, and different domains, rather than as a series of individual funding decisions. The portfolio logic acknowledges that most experiments will fail or produce ambiguous results, but that the few that succeed will justify the entire portfolio. It protects the exploration function from the death‑by‑a‑thousand‑cuts that occurs when each individual experiment is judged on its own success or failure.
Stage‑gated scaling. The curiosity budget funds small‑scale, safe‑to‑fail experiments. Successful experiments progress through stages of increasing scale and resource commitment, with explicit decision gates at each stage that require demonstrated evidence of effectiveness. The stage‑gated structure ensures that the exploration budget is not captured by programmes that have become too large to fail—the mechanism by which pilot programmes become permanent, unevaluated entitlements.
Independence of allocation. The decisions about which explorations to fund are made by bodies that are independent of the exploitation institutions that would benefit from or be threatened by the knowledge generated. A research council that allocates curiosity budgets to government agencies based on scientific peer review of the proposed experiments, rather than on the political preferences of the agencies themselves, is one institutional form.
Protected curiosity budgets are the governance equivalent of the exploration bonus in the dual control objective function. Without them, the controller will systematically under‑explore relative to the optimal policy—not because it is irrational, but because the institutional structure does not allow it to internalise the long‑term benefits of the information its explorations would generate.
6.5 Mandatory Model Review and Paradigm Replacement Cycles
Model lock‑in—the persistence of a model beyond its correspondence to reality, sustained by the institutional immune system—is the failure mode that separates systems that can update their understanding from those that cannot. The design response is to institutionalise the model review and replacement function, so that it does not depend on the voluntary self‑correction of the institutions that maintain the model.
Mandatory model review means that the major models on which governance decisions depend—macroeconomic forecasting frameworks, demographic projections, climate sensitivity estimates, regulatory impact models, security threat assessments—are subject to periodic, scheduled, independent review. The review is not triggered by crisis or by the discretion of the model's owners. It is a recurring institutional event, like a financial audit or an election, whose occurrence does not depend on anyone's judgment that the model might be wrong.
The structural properties of an effective model review architecture include:
Independence of the reviewer. The body that conducts the review is independent of the institution that maintains the model. An economic forecasting model reviewed by the same finance ministry that uses it for budget preparation is not being independently reviewed. The reviewer must have the institutional standing, the technical capacity, and the protected budget to conduct a thorough assessment and to publish findings that are uncomfortable for the model's owners.
Pre‑specified review criteria. The criteria against which the model is assessed—its predictive accuracy, its calibration, its coverage of relevant variables, its handling of uncertainty—are specified in advance and applied systematically. The specification prevents the post‑hoc adjustment of standards that occurs when a model's defenders scrutinise disconfirming evidence more aggressively than confirming evidence.
Paradigm replacement authority. The review body has the authority to trigger a paradigm replacement process when the model's performance falls below a specified threshold for a sustained period. The replacement process does not dictate what the new model should be—that is a scientific and technical question—but it mandates that the existing model can no longer serve as the official basis for decision‑making, and it requires the model's owning institution to develop, test, and transition to an alternative within a specified timeframe. The authority to retire a model is as important as the authority to review it.
Public transparency. The review findings, the evidence on which they are based, and the response of the model's owning institution are all public. Transparency serves multiple functions: it prevents the suppression of unfavourable reviews, it enables the broader epistemic community to scrutinise the review's own methodology, and it builds the legitimacy of the review process over successive cycles.
The model review cycle is the institutional analogue of the model validation step in adaptive control—the periodic check that the internal model still corresponds to the system it claims to represent. The scientific community's peer review and replication mechanisms perform this function for scientific models. Governance systems require analogous mechanisms for the models on which their decisions depend, and those mechanisms must be protected from the institutions whose models they may invalidate.
6.6 Institutionalised Forgetting
Retaining only what remains useful is as important as retaining what is learned. The forgetting‑without‑learning trap of Section 3.5 demonstrates that systems with weak institutional memory lose knowledge faster than they acquire it. But the complementary pathology—retaining obsolete models, programmes, and institutional arrangements beyond their useful life—is model lock‑in sustained by the absence of a forgetting function.
Institutionalised forgetting is the deliberate design of mechanisms that enable the peaceful retirement of programmes, policies, and institutional arrangements that no longer serve their purpose. The forgetting is not amnesia—the destruction of memory—but curation: the active, discriminating removal of what is no longer useful to make space for what is.
The design mechanisms include:
Sunset clauses. Legislation and programmes are enacted with a pre‑specified expiration date, after which they terminate automatically unless explicitly reauthorised. The burden of proof is on continuation, not on termination. Sunset clauses invert the default: instead of programmes persisting indefinitely unless a political coalition musters the will to kill them, programmes die unless a political coalition musters the evidence to sustain them.
Zero‑based budgeting cycles. Rather than taking the previous year's budget as the baseline and debating increments, zero‑based budgeting requires each programme to justify its entire budget from scratch on a periodic cycle. The cycle forces an explicit re‑evaluation of the programme's continued value, generating the information that the forgetting function requires. The cycle must be long enough that the re‑evaluation burden is manageable—annual zero‑based budgeting for an entire government would be administratively impossible—but frequent enough that programmes do not persist for decades without scrutiny.
Mandatory programme evaluation with automatic termination triggers. Programmes above a specified size threshold are subject to rigorous impact evaluation on a scheduled cycle. Programmes that fail to demonstrate effectiveness against pre‑specified criteria across multiple evaluation cycles are automatically terminated, not subject to political discretion. The automatic trigger removes the need to assemble a political coalition to kill a specific programme—a collective action problem that systematically favours the persistence of ineffective programmes whose beneficiaries are concentrated and organised while their costs are diffuse.
Constitutional or statutory review mechanisms. The largest‑scale forgetting function is the capacity to peacefully retire entire institutional arrangements that no longer serve their purpose. Constitutional review mechanisms—citizens' assemblies, constitutional conventions, periodic referendums on constitutional continuity—are the institutional forms of this function. They must be designed to be difficult enough to activate that they are not triggered by transient political pressures, and accessible enough that they are available when the gap between the constitutional architecture and the society it governs has become structural.
The forgetting mechanisms must themselves be protected from capture by the interests that benefit from the retention of what should be forgotten. A sunset clause that can be overridden by a simple majority in the legislature is not a forgetting mechanism; it is a renewal ritual. A programme evaluation function whose budget is controlled by the ministry whose programmes it evaluates is not an independent assessor. The forgetting function requires the same structural protections as the exploration function: independence, protected budgets, and pre‑committed decision rules.
6.7 Learning Rate Accelerators
The rate at which a governance system learns is constrained by the rate at which it can conduct experiments and the rate at which it can process their results. These rates are not fixed by the nature of governance. They are functions of the infrastructure—data, analytical capacity, simulation capability—that the system maintains. Learning rate accelerators are investments in that infrastructure.
Data infrastructure for near‑real‑time outcome visibility. The traditional governance learning cycle is slow because outcomes are measured infrequently and reported with long lags. Administrative data systems that capture outcomes continuously—tax receipts, healthcare utilisation, school attendance, regulatory compliance—can compress the observation latency from years to weeks. The investment is not primarily technological; the technology exists. It is institutional: the integration of administrative data systems across agencies, the standardisation of data formats, the resolution of privacy and confidentiality constraints, and the creation of analytical capacity to process the resulting data streams.
Digital twins and policy simulation environments. A digital twin is a computational model of a governance system—a city's transport network, a region's labour market, a national health system—that is calibrated against real‑time data and can be used to simulate the effects of policy interventions before they are implemented in the physical world. The digital twin does not replace real‑world experimentation—it is itself a model, subject to the same model drift as any other—but it can accelerate the exploration cycle by enabling high‑frequency, low‑cost, safe‑to‑fail experimentation in silico. The results of in‑silico experiments inform the design of real‑world pilots; the results of real‑world pilots update the digital twin. The two modes of exploration are complementary.
Embedded methodological capacity. The analytical techniques required for rigorous policy learning—causal inference from observational data, experimental design for randomised controlled trials, Bayesian updating for sequential learning, machine learning for pattern detection in high‑dimensional administrative data—are sophisticated and scarce. Embedding this capacity within the governance apparatus, rather than outsourcing it to academic researchers or consultants whose involvement ends when the study is published, is a structural requirement for sustained learning. The capacity must be career‑track: positions that attract and retain talented quantitative analysts within the public sector, with competitive compensation, intellectual autonomy, and career progression that does not require moving into generalist management.
Learning repositories and knowledge management. The forgetting‑without‑learning trap is partly a failure of knowledge management infrastructure. Evaluation results, programme data, and the tacit knowledge of practitioners must be systematically archived, curated, and made accessible to successors. The infrastructure includes not only databases but also the institutional practices—handover documentation, exit interviews, after‑action reviews—that ensure knowledge is transferred when personnel turn over. The learning repository is the institutional memory that the forgetting factor λf represents in the formal model. Its quality determines whether the system's effective λf is close to unity or close to zero.
6.8 Antifragility Through Stress Exposure
The series' final design principle reframes the concept of antifragility in control‑theoretic terms and derives its institutional implications.
A system that never experiences stress cannot learn the parameters that determine its response to stress. This is not a philosophical claim about the virtues of adversity. It is a direct consequence of the persistent excitation condition: if the input signal never excites the system's nonlinear or extreme‑regime dynamics, those dynamics are not identifiable from the available data. The system's model of itself is calibrated to the narrow range of conditions it has experienced, and it is maximally uncertain—or, worse, confidently wrong—about its behaviour outside that range.
A governance system that suppresses all variance—all protests, all policy failures, all external shocks, all dissenting information—is therefore not maximally stable. It is maximally fragile. It has eliminated the excitation on which model identification depends. Its apparent stability is the stability of a controller that has never been tested—a stability that is indistinguishable, from inside the system, from the genuine robustness that comes from having been tested and having learned.
The design implication is not that governance systems should seek catastrophe. It is that they should maintain deliberate, bounded exposure to the stressors that reveal their own parameters.
Stress testing of financial and infrastructure systems. Financial regulators should mandate periodic stress tests—simulated crises that reveal the system's vulnerability to shocks—and should vary the scenarios to prevent the system from optimising to a known test. Infrastructure systems should be subjected to load tests that exceed their design specifications, not to break them but to discover where they break. The stress test is a safe‑to‑fail exploration of the system's extreme‑regime dynamics.
Red‑team exercises for policy and strategy. A red team is an independent group tasked with challenging a policy, strategy, or assessment from an adversarial perspective. It functions as a deliberate injection of exploration variance into the policy process—a structured mechanism for surfacing assumptions, testing them against alternative frameworks, and revealing vulnerabilities that the consensus model has overlooked. The red team must be protected from the institutions whose policies it challenges, and its findings must be integrated into the decision process rather than shelved.
Citizens' assemblies and dissenting preference channels. A governance system that suppresses protest and dissent is suppressing a signal about its own performance—specifically, the signal that reveals the preferences and experiences of populations whose voices are not transmitted through the standard representation channels. Protected spaces for protest, contestation, and dissenting preference expression are not merely democratic niceties. They are observation channels that reveal parameters of the governed population's preferences and compliance behaviour that would otherwise be invisible to the controller. The system that suppresses them is suppressing the excitation it needs to remain calibrated.
After‑action reviews and failure autopsies. When failures occur—and they will, even in well‑designed systems—the governance architecture should mandate systematic, public after‑action reviews that extract the learning from the failure and embed it in the institutional memory. The review must be protected from the institutions whose failure is being examined, and its findings must be disseminated to the institutions that can act on them. The military's after‑action review process and the aviation industry's accident investigation system are partial models: they are institutionalised mechanisms for extracting maximum information from minimum failure frequency, and they have produced sustained improvements in safety and effectiveness over decades.
The eight design principles form an integrated architecture for adaptive governance. Protected experimental spaces generate the persistent excitation that makes learning possible (6.1). Safe‑to‑fail structures ensure that the failures inherent in exploration are survivable and informative (6.2). Separation of exploration and exploitation functions protects the learning apparatus from the short‑term pressures that would extinguish it (6.3). Protected curiosity budgets provide the dedicated resources that the exploration bonus requires (6.4). Mandatory model review and paradigm replacement cycles prevent model lock‑in (6.5). Institutionalised forgetting enables the peaceful retirement of what no longer serves (6.6). Learning rate accelerators increase the speed at which the system can acquire and process information (6.7). And antifragility through stress exposure ensures that the system's model is calibrated across the full range of conditions it may encounter (6.8).
None of these principles is easy to implement. Each confronts the political incentives that make short‑term exploitation more attractive than sustained exploration, and each requires institutional protections that the immune system will resist. But the alternative is not a different governance strategy. It is the continued operation of the learning failure modes that Part III diagnosed—exploration starvation, model lock‑in, exploitation lock‑in, learning‑induced oscillation, and the forgetting‑without‑learning trap—until the accumulated gap between the system's model and its environment breaches a crisis threshold. The structural logic is clear. The design requirements follow from it. The task of implementation is the work of building institutions that take their own learning as seriously as they take their performance.
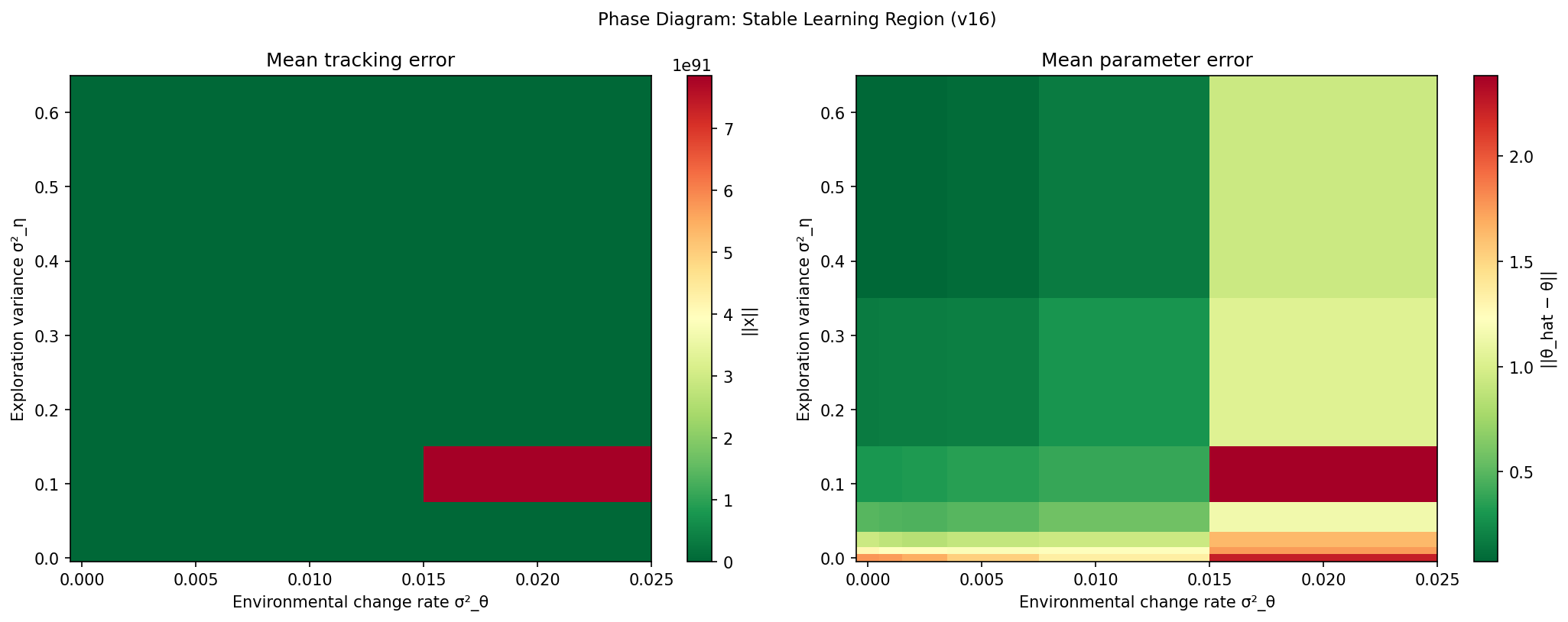 Left panel: Mean tracking error
Left panel: Mean tracking error 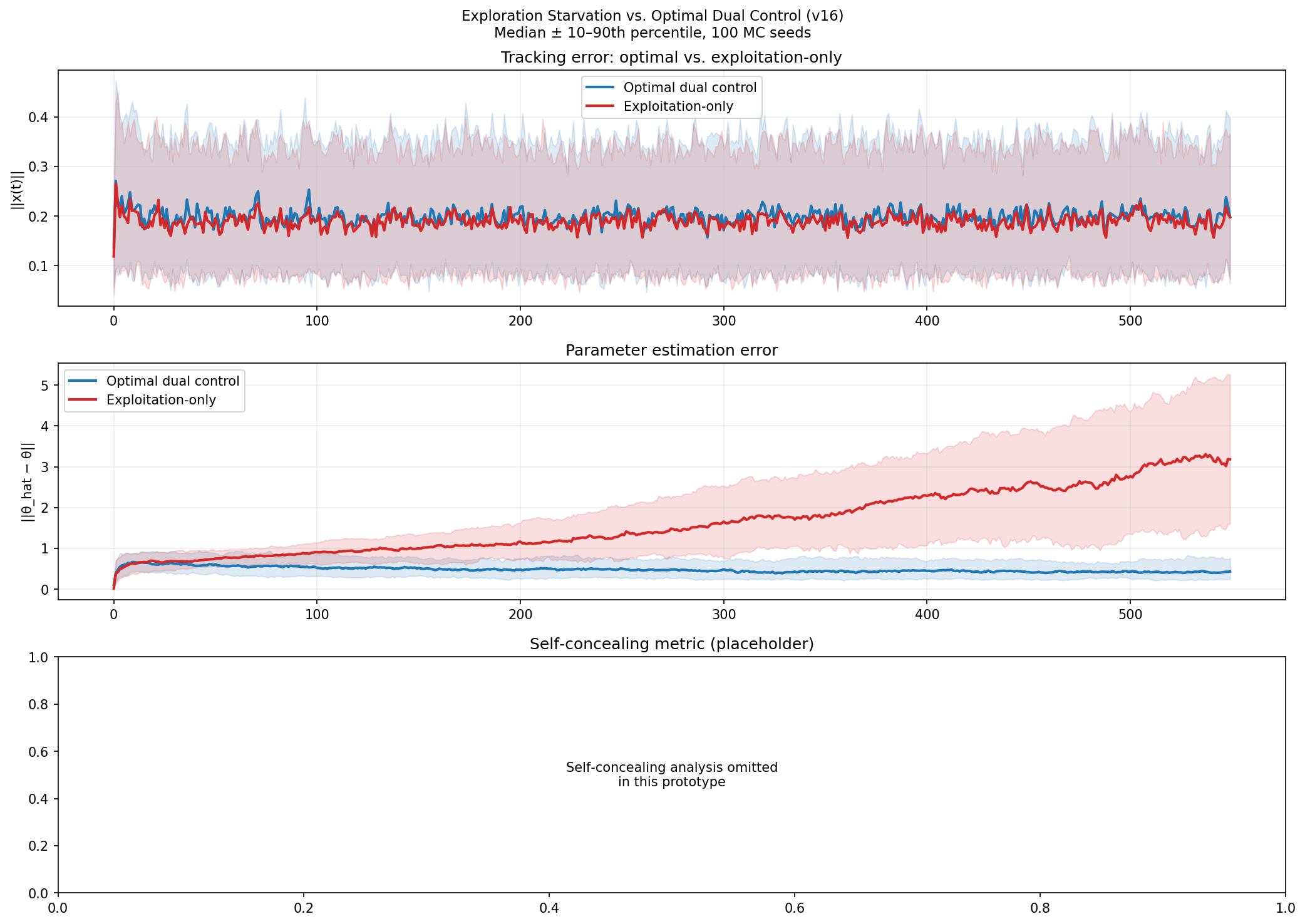 Top panel: Tracking error over time for the optimal dual controller (Scenario 1, blue) and the exploitation‑only controller (Scenario 2, red). The exploitation‑only controller initially matches or slightly outperforms the dual controller, but its error diverges upward after approximately
Top panel: Tracking error over time for the optimal dual controller (Scenario 1, blue) and the exploitation‑only controller (Scenario 2, red). The exploitation‑only controller initially matches or slightly outperforms the dual controller, but its error diverges upward after approximately 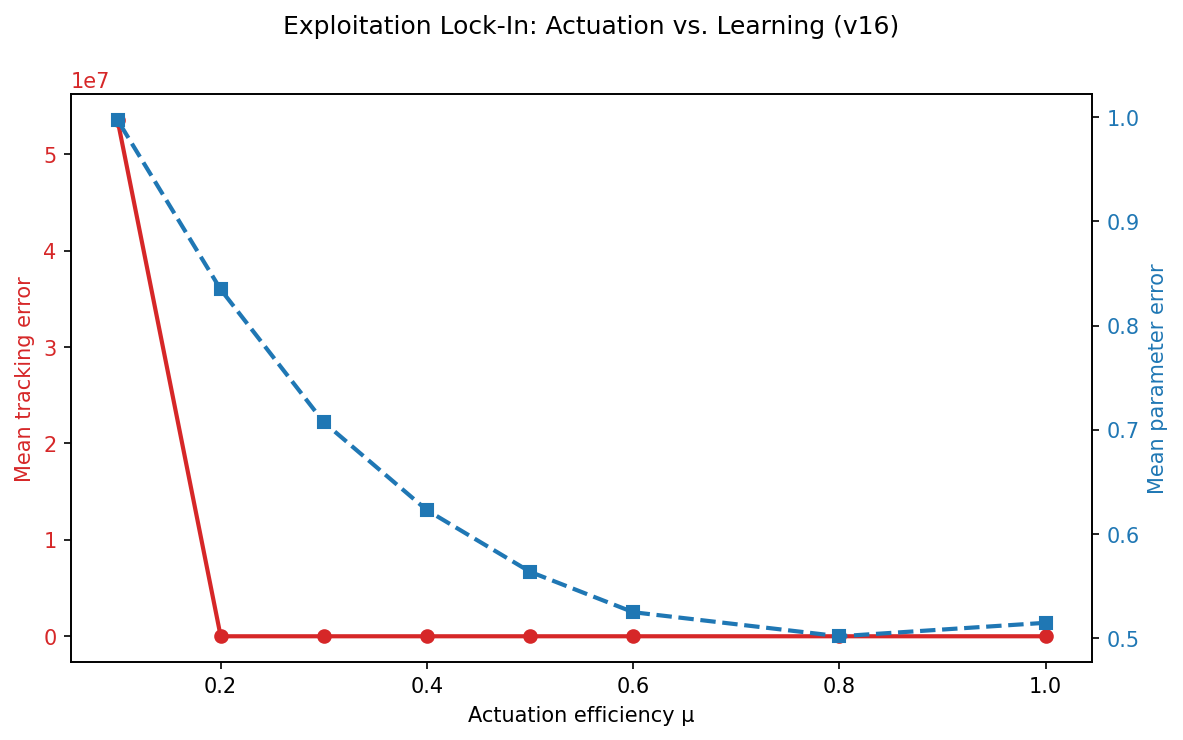 Tracking error (red, left axis) and parameter estimation error (blue, right axis) as functions of actuation efficiency
Tracking error (red, left axis) and parameter estimation error (blue, right axis) as functions of actuation efficiency 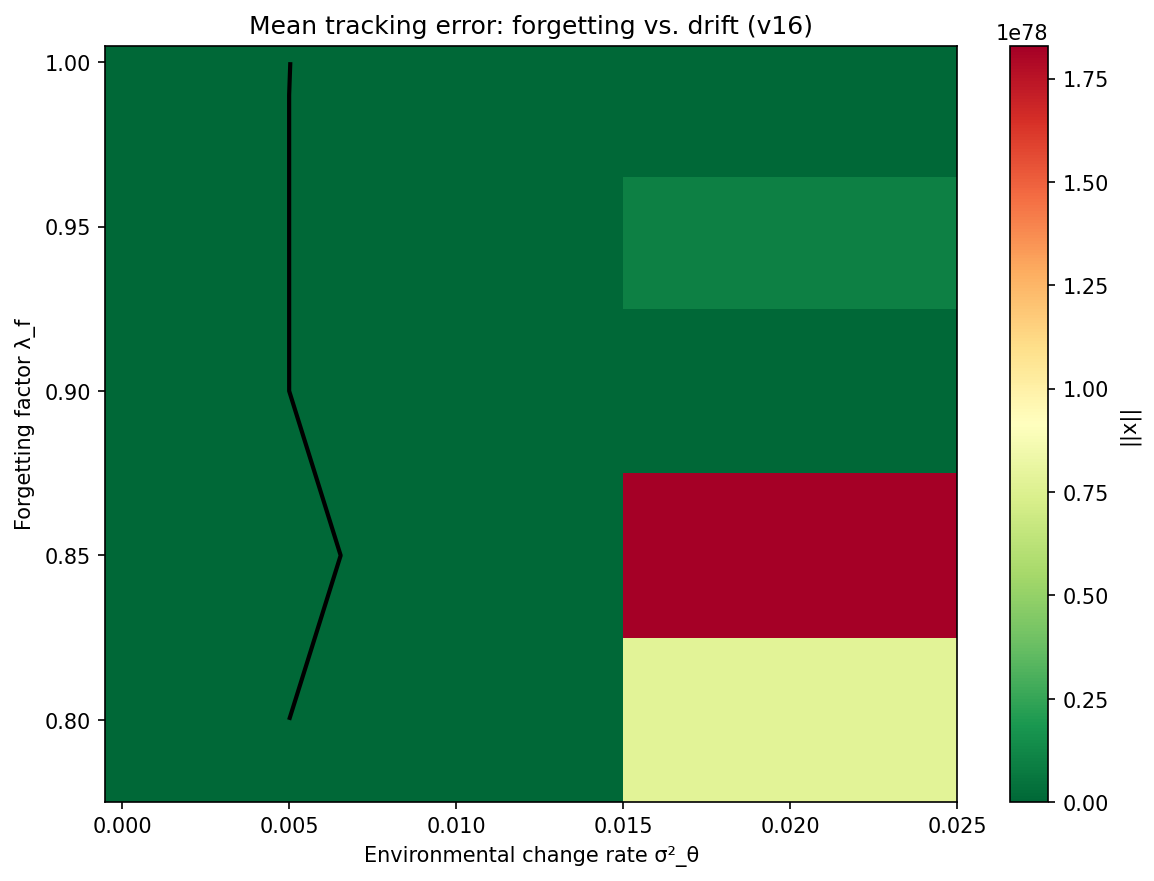 Mean tracking error as a function of the forgetting factor
Mean tracking error as a function of the forgetting factor